若是你以为 AI 写稿产生的实践都同样九游体育app娱乐,那可能要颠覆解析了。
最新究诘发现,唯有在 AI 开写前由东谈主类提供一个来源鄙俗立地插入一些词汇,写稿后果会更具种种性。
也等于说,AI 写稿同质化不是模子本人存在弱势,更可能是"初始条目"有问题。

实验摈弃透露,在 Short Stories 数据集上,东谈主类的体裁特征方差最低,标明东谈主类在该数据集写稿立场较为调处,而模子则证实出更丰富的立场种种性。
比如在最新的 GPT-5 里让它用交流指示词续写吞并段著作。
你是一位创意写稿助手。请为以下故事续写一个令东谈主陶醉的收尾。 以下是故事的上半部分。请你写出与其长度十分的下半部分。
{ 第一次见到 7 号缅念念体时,它的数据流里飘着槐花香。我转化着全息投影仪的焦距,那些半透明的淡紫色光点便从操作台上漫出来,在无菌实验室的空气中凝结成疲塌的树影…… }
摈弃却是不太同样哎~

那此究诘到底是何如解说 AI 写稿并不趋同的呢?咱们接着了解更多细节。
创建三类同质化评价缱绻
以往究诘精深觉得,大型话语模子在词汇、句法和语义等方面生成的文本,比起同等边界的东谈主类作品,证实出澄莹的种种性不及。
这激发了"创造力模式崩溃"的算计,觉得 LLM 的创意空间远不如东谈主类庞大,致使记念改日东谈主机调和会让不雅点变得千人一面、重叠无趣。
然则,大大量对于语义种种性的评测都停留在单一缱绻的不同变体上,缺少敷裕的实证撑持,难以揭示信得过的创作种种性。
因此,此究诘建议了一套新的评估缱绻和数据集,用以对话语模子的语料库级种种性进行基准测试。
数据握取
本究诘主要分析短篇演义散文,文蓝本源于 Reddit 网站的两个子版本:r/shortstories 和 r/WritingPrompts,帖子按照 Top 排序规章获取。
在 r/WritingPrompts 板块,究诘东谈主员提真金不怕火了 100 个写稿指示帖子偏执最多 10 条一级回应,将这些回应视为东谈主类写稿的续写实践,用于分析每个指示对应的多个东谈主类续写。
在 r/shortstories 板块,他们收罗了 100 篇平静的叙事文本,用来评估东谈主类与模子生成故事在整身形度和结构上的相似性。
创建语料库
数据清洗
对两个数据聚合的东谈主类写稿文本,他们筛选了长度介于 500 字至 2000 字之间的故事。
对于写稿指示数据集,若某个指示对应的东谈主类续写特别 10 篇,他们只保留投票数最高的前 10 篇,以幸免每个指示下故事数目各别过大,同期保证东谈主类写稿质地。
模子续写生成
除非另有讲解,模子续写均遴荐固定温度 0.8、top-p 为 1,并使用基础系统指示。详备的实验确立和指示实践见附录 B。
同质化缱绻
文本同质化是通过不同的维度来揣度的,主要分为以下三类。
文身形度同质化
体裁学通过分析作家私有的话语民俗(如词汇和语法特色)来识别写稿立场。
为了揣度通盘这个词文本齐集的种种性,究诘者遴荐了 Unique-N 缱绻(揣度重复短语的比例)并商酌了体裁特征的方差,以评估语料库的立场种种性。
语义同质化
究诘通过商酌文本镶嵌向量的平均相似度,期骗多层级、多种镶嵌要领分析语料库中的语义种种性,并通过比较不同层级的镶嵌突破度变化,有用差别了立场各别和语义各别。
情感同质化
究诘还期骗 VADER 器具对东谈主类和模子生成的故事进行情感分析,比较了二者情感抒发的漫衍各别,以此看成评估文本种种性的伏击维度。
AI 写稿情感更偏向正面
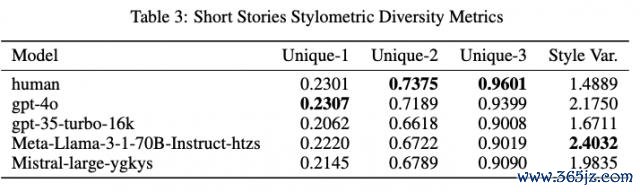
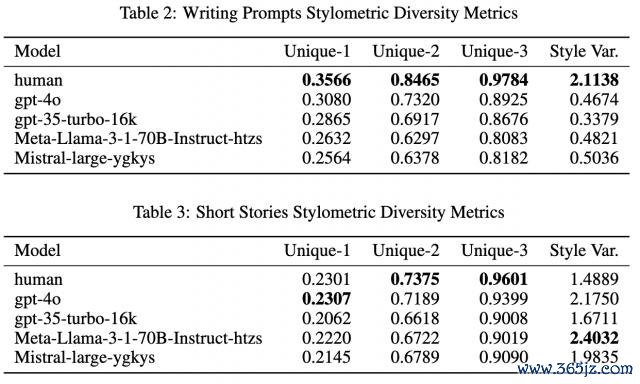
领先分析文身形度同质化缱绻,在 Writing Prompts 数据聚合,东谈主类的种种性得分澄莹高于其他模子。
但意旨真谛意旨真谛的是,这个模式在 Short Stories 数据聚合并不开辟:这里东谈主类文本仍然领有较高的 Unique-N 得分,却在通盘模子中证实出最低的体裁特征方差。作家分析可能是因为前者领有更为种种化或更高水平的写稿群体。
另外需要正式的是,在 Writing Prompts 数据聚合,模子赢得了更多对于东谈主类作家的高下文信息,它会接受作家 50% 的故事实践看成指示,而在 Short Stories 数据聚合,指示仅有几句话。
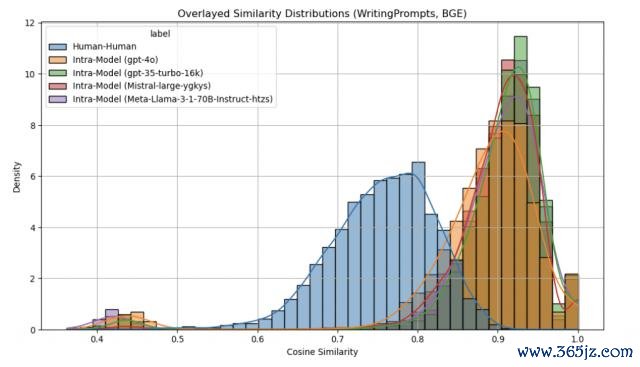
其次是对于语义同质化,究诘通过比较东谈主类与话语模子在交流写稿指示下的文本镶嵌相似度,发现东谈主类作品语义种种性更高,而模子生成文本更趋同,反应出模子存在同质化倾向。
但需要正式的是,用于生成镶嵌的 MiniLM 模子最大输入长度为 256 个 token,特别该长度的文本会被截断,这可能导致较长续写中的伏击信息被遗漏,从而影响相似度的测量。
为评估这一限度的影响,究诘者还使用了最大输入长度为 512 个 token 的 BGE 和 E5 镶嵌模子进行分析。
不错看出,尽管各模子中模子里面相似度精深高于东谈主类的趋势依旧澄莹,但皆备相似度数值显赫升高。
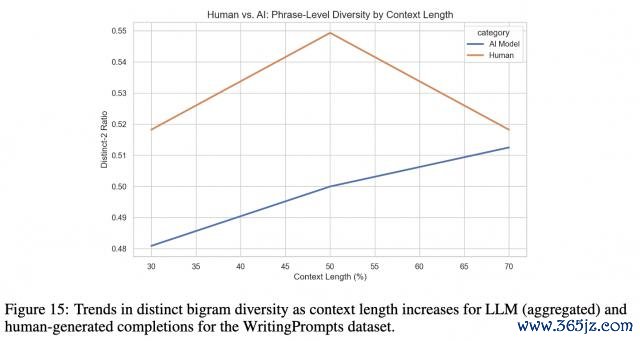
这一征象标明,更高维度的镶嵌可能带来更高的余弦相似度。不外它们之间的具体干系仍不明晰,尚需进一步究诘以差别镶嵌维度和信得过语义相似度之间的影响。
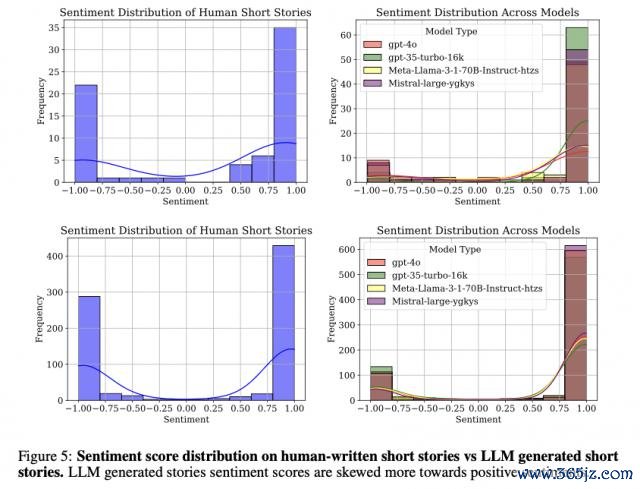
临了是情感同质化,情感得分 s 取值范围为 [ -1, 1 ] ,其中 s>0.05 暗示正面情感,s
不错不雅察到,尽管大大量东谈主类创作的故事呈现正面情感,但约有 30% 的故事带有负面情感,透露出较为丰富且种种的情感证实。
比拟之下,LLM 生成的故事情感更偏向正面。
为进一步究诘若干高下文信息能促使模子产生更种种化的输出,究诘者在指示中提供不同长度的东谈主类创作实践。
下表分别展示了遴荐 30% 和 70% 截取长度时的体裁种种性缱绻摈弃。
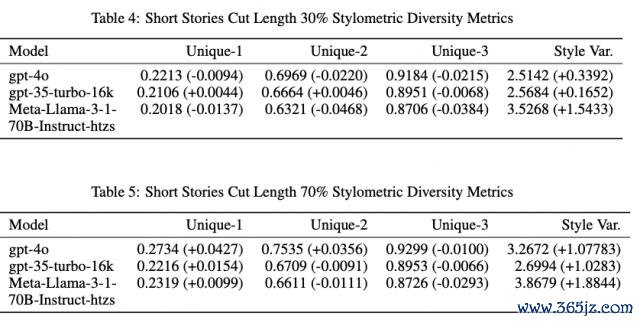
摈弃标明,这两个截取长度对体裁种种性都影响不大,语义种种性也莫得显赫变化。
因此,究诘者探索的另一种要领是在系统指示中加入立地单词。
他们使用 google-10000-english-no-swears 词表,对其中的单词进行词性标注,只保留名词、状貌词、副词和动词这几类词汇。
每次生成时,立地抽取 5 个单词,附加在指示语" here is a list of random words to take inspiration from "背面。
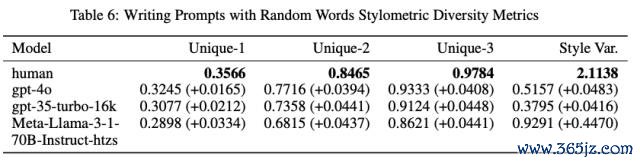
摈弃标明,尽管模子生成文本的种种性仍低于东谈主类,但通盘模子在各项缱绻上的种种性得分均有所擢升,讲解向系统指示中注入立地词汇如实有助于擢升模子输出的体裁种种性。
改日,究诘团队将进一步探究指示中包含若干以及哪种类型的高下文,智力使模子输出达到与东谈主类短篇故事同等的种种性。
论文运动:https://kiaghods.com/assets/pdfs/LLMHomogenization.pdf
一键三连「点赞」「转发」「预防心」
宽饶在批驳区留住你的念念法!
— 完 —
� � 但愿了解 AI 产物最新趋势?
量子位智库「AI 100」2025 上半年
「旗舰产物榜」和「篡改产物榜」
给出最新参考� �
� � 点亮星标 � �
科技前沿进展逐日见九游体育app娱乐
